La musique vue par une informaticienne
Comment fonctionne Shazam?
Shazam est un logiciel très populaire qui permet d’identifier une pièce musicale, à partir du microphone d’un appareil mobile (téléphone, tablette, ordinateur portable). Vous êtes dans une boutique, vous entendez une pièce musicale que vous ne connaissez pas, vous pouvez utiliser cette application afin de retrouver toutes les informations pertinentes (le nom de la chanson, son interprète, etc).
Alors comment fait Shazam pour reconnaître la pièce que vous voulez identifier? Le problème c’est que l’identification d’une pièce musicale est encodée en clair dans ce qu’on appelle les métadonnées d’un fichier (mp3 par exemple).
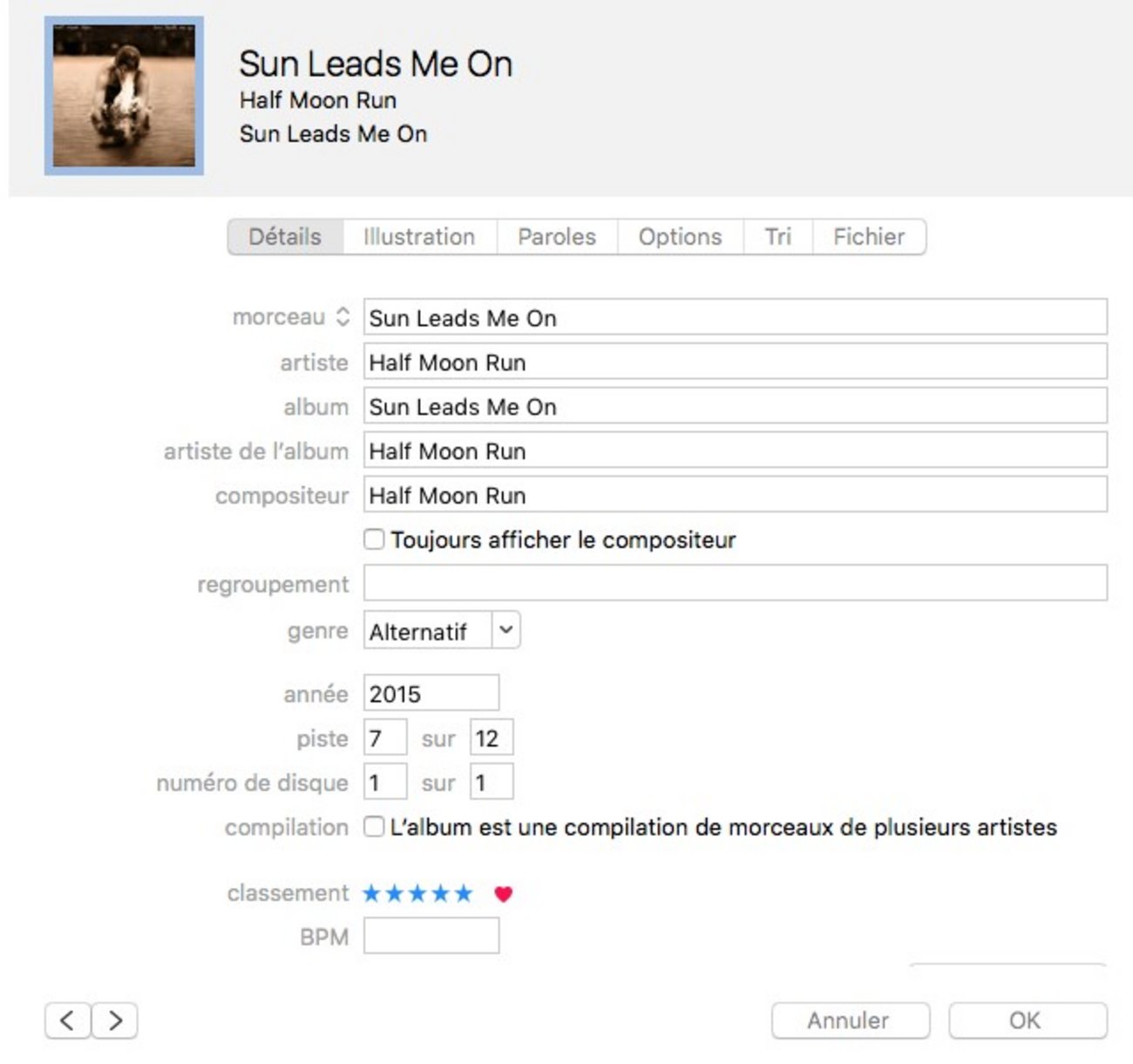
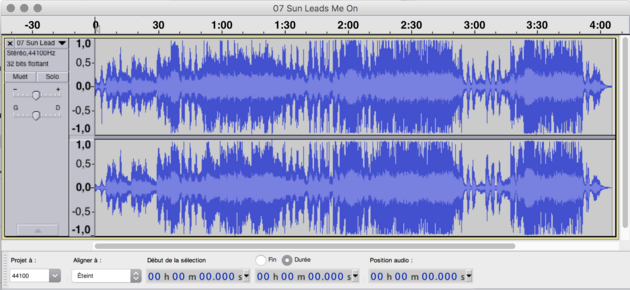
Ce sont des métadonnées textuelles qui sont très faciles à indexer et rechercher dans une base de données. En plus de ces métadonnées, le fichier contient la fonction d’onde sonore (compressée un peu ou beaucoup, c’est très variable).
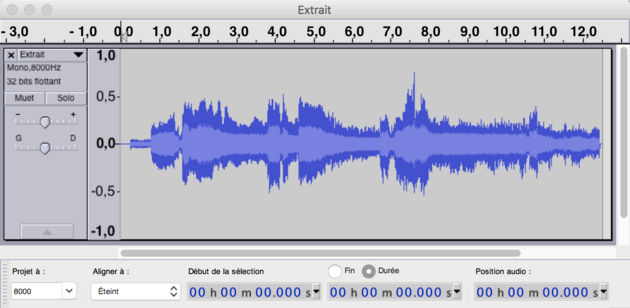
Si on enregistre un extrait sonore par le microphone de son téléphone, on n’a accès qu’à une partie de l’onde sonore de la pièce musicale.
Donc, comment faire pour retrouver rapidement l’information concernant les métadonnées à partir d’un extrait sonore qui n’en contient pas?
En comparant les 2 ondes sonores uniquement, on peut rapidement constater plusieurs différences :
- la durée en secondes n’est pas du tout la même;
- le nombre de canaux n’est pas pareil non plus (2 pour le fichier original car il est stéréophonique et 1 seul pour l’extrait car il est monophonique);
- la fréquence d’échantillonnage, c’est-à-dire le nombre d’échantillons sonores par seconde n’est pas le même (44 100 Hz pour la chanson et 8000 Hz pour l’extrait).
Sans compter le type de fichier, la compression, le débit, le volume...
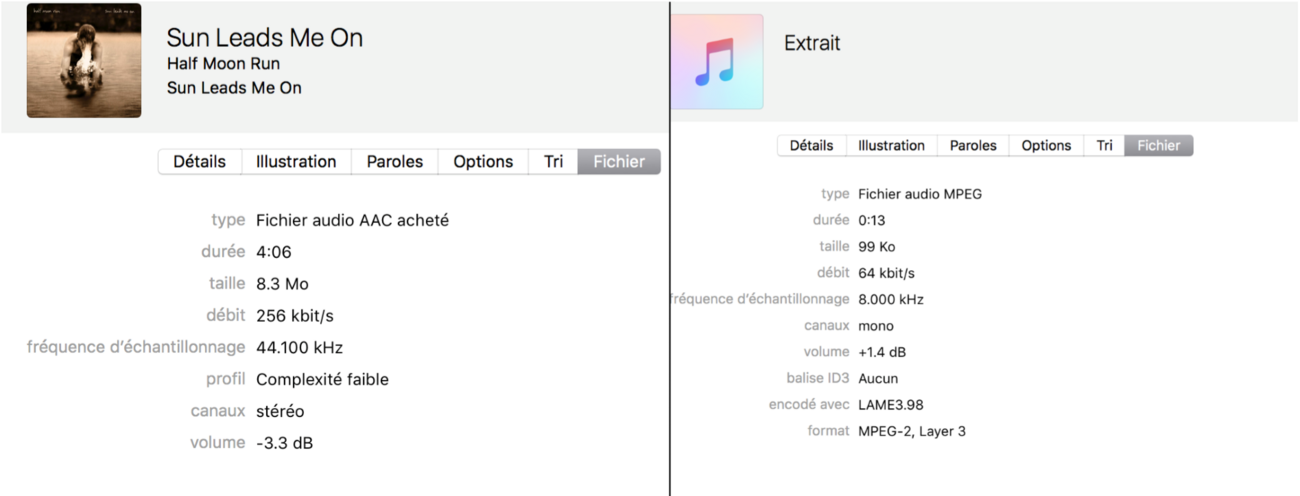
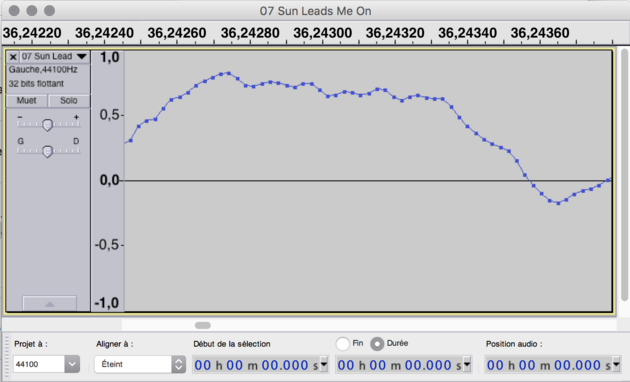
Si on regarde la fréquence d'échantillonage de plus près, on voit une bonne différence entre les deux extraits. Une fréquence de 8000 Hz représente 8000 échantillons par seconde. Donc, pour l’extrait de 13 secondes, on a 8000 Hz x 13 secondes = 104 000 échantillons et pour la chanson au complet, il y a 44 100 Hz x (4 minutes*60 secondes/minutes + 6 sec) éch/sec. = 10 848 600 échantillons, et ce, pour un seul canal.
Dans l’image de droite, chaque petit carré représente un échantillon et cette section de l’onde sonore est un peu moins de 2 millièmes de seconde.
Cela donne une idée de la quantité d’informations présentes dans une simple chanson.
On comprendra alors qu’il est impossible d’envisager de comparer les deux extraits par échantillon, cela prendrait beaucoup trop de temps et ce pour une seule pièce musicale. Imaginez comparer avec toute une base de données comportant des milliers, voire des millions de titres. C’est là le noeud du problème, il faut trouver une façon de réduire l’information numérique brute et de la résumer par des mesures qui auraient un sens musical. Ce type de résumé est appelé l’empreinte acoustique, car c’est une notion rappelant l’empreinte digitale.
L’empreinte acoustique est comme une signature sous forme de vecteur (un ensemble de nombres dans un ordre précis) qui représente le contenu musical au lieu des nombres de l’onde sonore originale. Elle permet de retrouver les métadonnées à partir d’un fichier audio non étiqueté (ou non identifié), à partir de l’onde sonore, de façon indépendante du format de fichier et des métadonnées.
Une bonne empreinte acoustique doit :
- réduire la dimension d’une onde sonore numérique en encodant des informations qui résument bien la pièce musicale (fréquences, tonalités, rythmes, etc);
- être indépendante d’un certain niveau d’interférences comme par exemple la présence de bruits ambiants;
- être représentative de la ressemblance perceptuelle de deux signaux audio et non de leur ressemblance échantillon par échantillon;
- être indépendante du niveau de compression ou même de la distorsion dans le signal;
- permettre de reconnaitre la pièce même s’il y a une intonation ou une vitesse différente;
- identifier la pièce à partir d’un extrait très court;
- et se calculer assez rapidement.
L’empreinte acoustique est donc calculée pour chacune des pièces dans la base de données qui sert de référence pour la recherche et emmagasinée sur un serveur avec toutes les métadonnées pertinentes. En effet, il serait peu efficace de refaire ce calcul pour chaque requête! Et cette empreinte est assez petite comparée au fichier original. En fait, on n’a même pas besoin de conserver l’onde sonore originale puisque ce qui nous intéresse ici, c’est d’avoir les métadonnées.
Ensuite, à chaque fois qu’on utilise l’application pour effectuer une recherche, l’extrait sonore est enregistré, il est modifié pour ajuster la fréquence d’échantillonnage, enlever du bruit, ajuster la compression, etc. Son empreinte acoustique est alors calculée et celle-ci sera comparée avec celles de la base de données de référence à l’aide d’une mesure de distance vectorielle. Il peut être avantageux d’organiser la base de données en familles de pièces qui sont semblables pour accélérer la comparaison. Chaque famille pourrait être résumée en faisant, par exemple, la moyenne des éléments de l’empreinte acoustique. La mesure de distance serait alors calculée avec celle de chaque famille et ensuite pour la famille la plus près, on calculerait la distance avec chacune des pièces la composant.
Les métadonnées de la pièce dont la distance avec l’extrait est la plus petite sera retournée comme réponse à l’utilisateur un peu magiquement! Évidement, si la distance minimale est trop grande, cela veut probablement dire que l’extrait ne fait pas parti de la base de données de référence. On essaie à nouveau avec une nouvelle chanson!
Professeure Marie-Flavie Auclair-Fortier
Département d'informatique